



Introduction
Apache Kafka is an open-source distributed event streaming platform that was designed to handle massive amounts of data in real time and is widely used by enterprises for building event-driven architectures.
In this blog, we'll explore the key features of Kafka, its architecture, and some of its use cases.
Key Features of Kafka:
Distributed: Kafka is a distributed system that can be run on multiple servers, allowing it to handle large amounts of data in real time.
Scalable: Kafka is highly scalable and can be easily scaled up or down depending on the needs of the system.
Fault-tolerant: Kafka is designed to be fault-tolerant and can continue to function even if a server or node fails.
Real-time processing: Kafka is designed for real-time processing, allowing it to handle large amounts of data in real time.
High throughput: Kafka can handle a high throughput of data, making it an ideal choice for processing large amounts of data.
Architecture
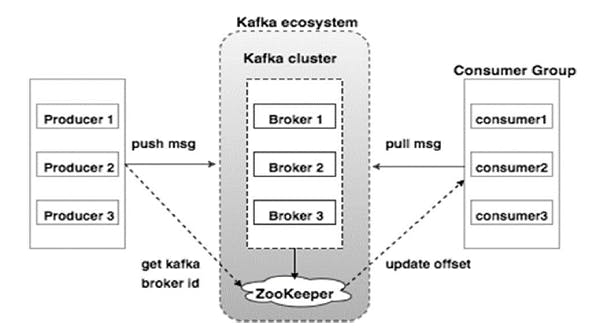
Kafka has a distributed architecture that consists of the following components:
Zookeeper: ZooKeeper is primarily used to track the status of nodes in the Kafka cluster and maintain a list of Kafka topics and messages.
Producer: A producer is responsible for producing data to Kafka. It can be a client application that generates data or a service that sends data to Kafka.
Broker: A broker is a server that acts as a message broker between the producer and consumer. It is responsible for storing and managing data in Kafka.
Consumer: A consumer is responsible for consuming data from Kafka. It can be a client application that reads data or a service that receives data from Kafka.
Topic: A topic is a category or stream name to which data is published by the producer. Topics are divided into partitions, which are stored across different brokers.
Partition: A partition is a sequence of messages that are stored in Kafka. Each partition is replicated across multiple brokers to ensure fault tolerance and high availability.
Use Case
Messaging: Kafka is used for messaging in distributed systems where it acts as a message broker between different components of the system. This is the biggest use case of Kafka to form a communication channel between a microservice architecture.
e.g. Messaging system between different services via Confluent (built on top of Kafka)
Real-time data processing: Kafka is widely used for real-time data processing in applications such as stock trading, online gaming, and social media.
Stream processing: Kafka is used for stream processing, which involves processing and analyzing data in real time as it is generated.
Conclusion
This was part 1 of the Kafka series which was a bit theoretical and introductory, if you want to learn more about the actual implementation, the next parts are coming soon...
I hope this helps! 💙